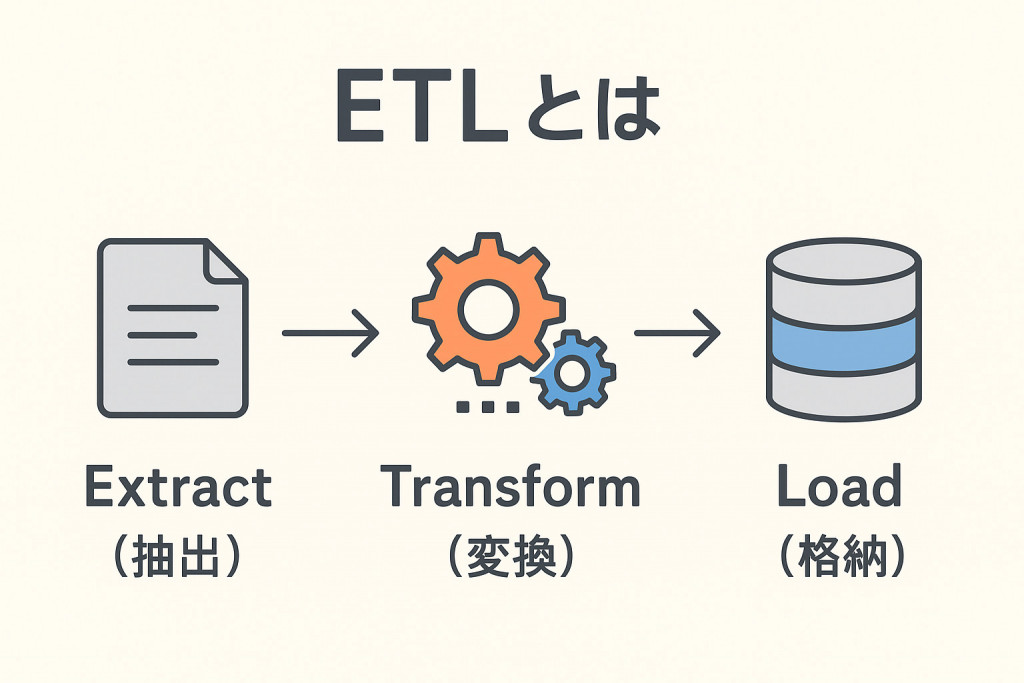
データ活用が企業競争力を左右するといっても過言ではない今、「ETL」という言葉を耳にする機会が増えています。ETLとは「Extract(抽出)」「Transform(変換)」「Load(格納)」の頭文字を取ったもので、複数のシステムに散在するデータを、分析・活用しやすい形に整え、一箇所に集約するデータ統合プロセスのことです。本記事では、ETLの基本的な仕組みから具体的な活用方法、導入のポイントまで、初心者にもわかりやすく解説します。
ETL(イーティーエル)とは何か

ETLは、データ統合※1 の基本的なプロセスで、1980年代のDWH(Data Ware House:データウェアハウス)※2 の登場とともに発展した技術です。ここでは、ETLとは何か、そしてなぜ今ETLが求められているのか、その背景を解説します。
※1 データ統合:複数のソースから抽出したデータを統一された汎用性の高い形式にまとめ、多様なシステムでの活用や分析を可能にすること
※2 DWH:組織内のさまざまな業務システムからデータを収集・統合し、意思決定のために最適化して保存するデータベースのこと
ETLとは
ETLとは、「Extract(抽出)」「Transform(変換)」「Load(格納)」の3つのプロセスから構成されるデータ統合の手法のことです。あくまでも手法なので、特定のツールやソフトウェアに依存するものではありません。
複数の異なるデータソースから必要なデータを取り出し、ニーズや技術要件に合った適切な形に変えて、最終的にターゲットシステム(DWHやデータベースなど)にロードする。ETLはこの一連の作業を指します。
POSシステムや顧客情報システムなど独立した異なるシステムで収集・保存されているデータは通常、別のシステムでは活用できません。データ形式が異なるためです。仮にそのまま分析しようとすると、異なるデータ形式別の集計や必要に応じたデータ変換などの作業に膨大な時間がかかってしまいます。
ETLを活用すれば、形式や収集先が異なるデータを統一した形式に変換し、一箇所に集約できるので、データ形式の違いや分散された状態に悩むことなくデータを分析・活用できます。
ETLは、ビジネスインテリジェンス(BI)※3データアナリティクス※4の基盤となる技術です。
※3 ビジネスインテリジェンス(BI):データを収集・分析・管理することで、ビジネス戦略策定や実務に役立つ知見や洞察を得るためのプロセス
※4 データアナリティクス:より優れた意思決定を可能とするための、データの分析・可視化を行う統計的手法、あるいは演算テクノロジーのこと
ETLが求められる背景
ETLが必要とされる背景には、データ環境の複雑化があります。
企業では多様なシステム(CRM※5 、会計システム、人事管理システムなど)が個別に稼働しており、各システムのデータはそれぞれ別個に保存されています。また、特に旧来から続く老舗企業では、オンプレミスとクラウドそれぞれのデータソースが混在(後述)し、データ環境が非常に煩雑としている状況も珍しくありません。さらには、IoTデバイスの普及により、センサーやデバイスから生成されるデータ量も増加の一途をたどっています。
※5 CRM:Customer Relationship Management:顧客関係管理
このように多様なシステムやデバイス等にデータが散らばっている状態では、複合的にデータを活用するどころか、所在を把握すること自体が大変困難です。
例えば、営業部門が顧客の購買傾向を分析したいと考えても、販売データは販売管理システムに、顧客の問い合わせ履歴はCRMに、顧客の基本情報は別のマスタデータベースに保存されている、といった具合です。これらの散在したデータを都度各部門に問い合わせて照会するなどして、手作業で集めて分析するには、膨大な時間と手間がかかります。
データを活用した経営戦略の必要性が増し、データドリブンな意思決定が求められる中、このような状況は企業の競争力を大きく損なうことでしょう。ETLを活用すれば、保存場所や保存形式の違いを意識せずに目的のデータを容易に検索でき、高度な経営分析が可能になります。
ETLは今や、データ活用の第一歩として不可欠な技術となっているのです。
ETLの3つのプロセス
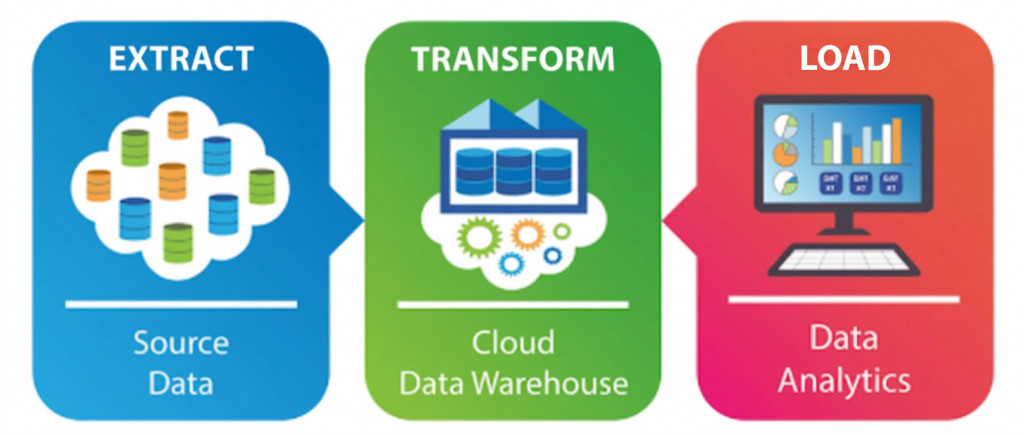
ETLの中心は、Extract(抽出)、Transform(変換)、Load(格納)の3つのプロセスです。それぞれのフェーズでデータを効果的に処理することによって、分析・活用のために使用できる最適な形に整えます。ここでは、各プロセスについて具体的な処理内容を詳しく解説します。データがどのように流れ、どのように変換されていくのかを理解することで、ETLの全体像が見えてきます。
Extract(抽出):データソースからの取得
Extract(抽出)は、多様なデータソースからデータ自体を取得する、ETLの最初の一歩となるプロセスです。
データソースには、データベース、クラウドストレージ、API、IoTデバイス、あるいはデバイスから書き出しされたCSVファイルやエクセル形式のファイルなど、多様な種類があります。抽出する場所も、基幹システム、業務アプリケーション、外部サービスなど多種多様です。
抽出のプロセスにおいては、必要性に応じたデータだけを得るために、事前に利用目的を明確にすることが求められます。たとえば、過去3ヶ月間の売上分析を行いたい場合には、10年分のデータをすべて抽出するのではなく、過去3ヶ月間のデータのみを抽出するといった具合です。
また、定期的に同じソースから同種のデータを抽出する場合には、特定の期間に変更があったデータのみを抽出する「増分抽出(インクリメンタル抽出)」という方法があります。記録されたすべてのデータをそのまま抽出すると処理時間が膨大になるため、フィルタリング機能を駆使して分析に必要なデータだけに絞り込むことで、データの抽出効率を向上させることができます。
参考:AWS『ETL(抽出、変換、ロード) とは何ですか?』
Transform(変換):データの加工と整形
Transform(変換)は、別個のアプリやシステム間で得られた別々のデータのデータフォーマット・属性・文字コード等を統一し、最終保存先(ターゲットシステム)への書き出しに適した形に変換・加工するプロセスです。
このプロセスでは、データのクレンジング(誤ったデータの修正、書式の統一、重複データの削除、欠損値の処理など)を中心に実施します。さらに、データの統合(複数ソースからのデータを結合)、データ型の変換(文字列・数値などへの変換、日付形式の統一など)なども作業内容に含まれます。
たとえば、A店舗では顧客の性別を「男性/女性」と記録し、B店舗では「M/F」と記録している場合、これらを統一した形式に変換する必要があります。また、日付が「2025/11/15」と「2025-11-15」のように異なる形式で記録されている場合も、統一した形式に変換します。
ニーズや技術要件に応じてデータを変換し、整理することで、後の分析作業がスムーズに行えるようになるでしょう。
Load(格納):データウェアハウスへの書き込み
Load(格納)は、変換が完了したデータを最終保存先(ターゲットシステム)に移動するプロセスです。
DWH(データウェアハウス)やデータレイク※6など、保存先に合った形式でデータを書き込みます。ターゲットシステムにデータを格納するプロセスを経てようやく、さまざまなデータソースから集約された横断的なデータを分析・活用できる準備が整った状態になるのです。
※6 データレイク:あらゆる形式のデータを生データのまま大量に蓄積するためのストレージ基盤
ETLのプロセスを経ることで、意思決定者やデータアナリストがターゲットシステムへアクセスし、データを検索・閲覧できる環境が実現され、戦略策定や経営判断へと活かされていくことになります。
ロード方法には、一括ロード(フルロード:全データを一度に格納)と増分ロード(インクリメンタルロード:差分データのみを追加)があり、データの更新頻度や量に応じて適切な方法を選択します。データの整合性を保ちながら、効率的にロードするための最適化が重要です。
ETLツールとは

「ETLツール」は、以上のようなETLのプロセスを効率的に処理するために開発されました。ETLツールが普及する前は、企業ではExcelやスプレッドシートを使い手作業でデータを収集・加工していましたが、近年の圧倒的なデータ量の増加・多様化とともに、手作業でのETLが難しくなってきました。手作業でのETLは、膨大な時間と労力がかかるだけでなく、ヒューマンエラーのリスクも大きく、属人化の問題も深刻です。現在では、こうした課題を一手に解決へ導くETLツールの活用が増えています。
従来の手作業の課題とETLツールの登場
従来、企業ではExcelやGoogleスプレッドシートを用いた手作業のETLが一般的でした。手作業とはいえ自作のマクロやスクリプトを使うなど、一定の効率化・自動化の工夫はあったものの、手作業でのETLには多くの課題がありました。
手作業によるETL、データ統合には以下のような問題点があります。
・データ量の爆発的増加や多様化による、処理時間や労力の膨大化
・手作業によるミス(入力ミス、コピーペーストミス、計算ミス、更新漏れなど)の発生リスク
・品質が担当者の知識やスキルに依存する(属人化)
近年の経営判断に必要なデータ量が膨大で手作業では追いつかないという物理的限界もそうですが、一層深刻なのは手作業が生むヒューマンエラー、属人化で、こうした問題が品質のばらつきや低下を招き、肝心の経営判断を誤るという事態になりかねません。
これらの課題を解決するために、ETLツールが登場しました。ETLツールを活用することで、データ統合の自動化・効率化が実現。近年では、プログラミングに関するスキルや知識がなくても気軽に利用できるETLツールも登場するなど、より簡単にETLプロセスを導入できる環境が整っています。
ETLツールの基本機能と種類
ETLツールには、オンプレミス型(自社サーバーにツールをインストールする)とクラウド型(インターネット経由の仮想環境でツールを利用する)の2種類があります。
オンプレミス型は、サーバーを自社内で保有・管理しているため安定したパフォーマンスが見込めます。そして、完全に社内環境内でETLプロセスを完結できるのでセキュリティ的にも安心です。一方、拡張性が低く増設が簡単にはできず、初期費用や導入までのリードタイムなどのコストがかかる傾向にあります。
対してクラウド型は、通信事業者が設備を保有・管理し、インターネットを経由して遠隔で利用するタイプのツールです。場所に関係なく利用でき、初期費用や保守管理にかかるコストが最小限で済み、柔軟なリソース拡張も行える一方で、パフォーマンスやセキュリティレベルを通信事業者のクオリティに依存してしまうリスクがあります。
ETLツールには、単にプロセスを自動化してくれるだけでなく、定期的にETLプロセスを実行してくれるスケジューリング機能や、問題発生時の原因特定と対応をより確実なものにできるエラーハンドリングやログ管理機能など、多くの利点があります。
ETLツールには色々な種類がありますので、企業規模や予算、技術要件、セキュリティ要件に応じて最適なツールを選択しましょう。
DWH(データウェアハウス)とETL

「DWH(データウェアハウス)」は、複数のデータソースからのデータを一元的に集約・格納するための、データベースの一種です。より噛み砕いて説明すると、企業の様々なシステムから集められたデータを蓄積し、分析・活用に適した形で保管する「データの倉庫」。DWHはETLにおける主要なデータ供給先であり、両者は密接に連携しています。ここでは、DWHの基本概念とETLとの関係性について解説します。
DWH(データウェアハウス)とは
DWH(Data Ware House)は、直訳すると「データの倉庫」で、企業内の複数システムからロードした大量のデータを、時系列などで構造化し蓄積するためのデータサーバーです。
DWHを提唱した米国のコンサルタント、ビル・インモン(William H.Inmon)氏による定義では、”目的別に(subject-oriented)統合化され(integrated),時系列で保管し(time-variant),更新をしない(non-volatile)」という特徴を持つ、マネジメントの意思決定を支援するデータの集合体”とされています。
引用:第11回日本医療情報学会春季学術大会 企画セッション(シンポジウム)『データウェアハウスとデータ利活用』
DWHでは、データを主題(subject)ごとに整理して、時系列で格納します。DWHでは構造化データを保存するため、格納時には通常「変換してからロード」するETLのプロセスをとります。(一部の最新のシステムでは、「ロードしてから変換する」ELTの形を取ることもあります)
DWHの最大の特徴は、先の定義通り、「データが消去されたり更新されたりせずに、時系列で蓄積されていく」点です。通常のシステムでは、情報が更新されると古いデータは上書きされてしまいますが、DWHでは過去の履歴データを保持した状態で最新データを保存します。こうした特徴を持っていることで、過去数年間・十数年間といった長いスパンでのトレンド分析や、前年同期比較などが可能になります。
DWHはこのように、効率的かつ統合的なデータ分析に適した構造を持っているのです。そのため、経営分析、マーケティング分析など、多様なデータを活用したより確実性の高い意思決定に活用できます。
ETLとDWHの連携の仕組み
ETLはDWHへのデータ供給を主な目的とする技術であり、DWHはETLによる構造化データの格納を前提としたデータベースです。つまり、両者は一体として機能しています。
ETLのプロセスによって適した形に変換されたデータがDWHに格納されることによって、データは柔軟に検索でき、分析・活用可能な状態になります。併せてETLツールを活用し、データの抽出から格納までの一連のプロセスを自動的、かつ定期的に実行することにより、DWHに格納されているデータを常に最新の状態に保つことができるのです。
ETL(ツール)を活用するメリット
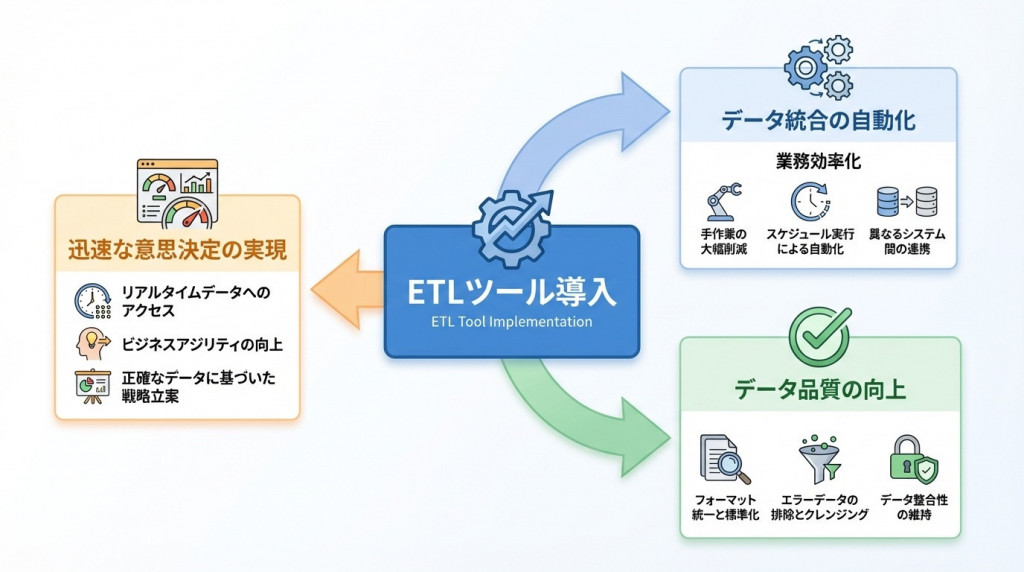
ETLツールを導入することで、企業は多くのメリットを享受できます。データ統合の自動化による業務効率化はもちろん、データ品質の向上、迅速な意思決定の実現など、その効果は多岐にわたります。ここでは、ETLを活用することで得られる具体的なメリットを解説します。
手作業からの脱却と業務効率化
ETLツール導入の最大のメリットは、手作業によるデータ統合を大幅に削減できることです。
特に多種多様なソースからのデータ収集やデータ加工作業は、手作業だと膨大な時間や労力を消費することになります。従来はExcelやXML、CSVファイルなどを使って数時間かけて行っていた作業を、ETLツールで自動化することで、数分〜数十分で完了できるようになります。
業務効率化の観点でいえば、最新のデータを定期的に自動処理できるスケジューリング機能は非常に重要です。従来、同じ種類のデータを同じ手順で定期的に収集・加工・格納する反復的な手作業は、日々のルーティンワークとして負担が定常化していました。しかし、ETLツールのスケジューリング機能によってこうした反復的で負担が大きい作業を自動化できます。営業時間外の土日で実施することも可能となります。
ETLツールを使うことで、担当者は反復的なデータ処理作業から解放され、分析や戦略立案など、より付加価値の高い業務に時間を使えるようになります。
データ品質の向上と属人化の解消
ETLツールの大きな利点は、データクレンジング機能を使えることです。
データクレンジング機能により、誤りのあるデータ、データの重複、異なるフォーマットの併存、値の欠損などを自動で検出・修正・統一できます。こうした自動化によって、手作業によるミスを削減し、より信頼性の高いデータを常に取得可能な状態となるのです。
属人化の解消も、相対的なデータ品質向上につながる大きなメリットです。手作業では特定の担当者のノウハウに依存していたため、データの品質にばらつきがありました。ETLツールを使うことで、品質の高い担当者のノウハウを標準化・自動化でき、誰でも同じ品質のデータ処理ができる状態が期待できます。
迅速な意思決定とビジネス価値の向上
ETLツールは、リアルタイムまたは定期的なデータ更新が可能であるため、常に最新のデータに基づいた確度の高い意思決定を可能にします。
多くの企業では、夜間バッチ処理と呼ばれるETL処理を行っています。業務時間外である夜中の間にETL処理を自動で実行することで、翌朝一番に最新データが反映された状態でDWHを参照できるような体制になっているのです。(業務時間内におけるネットワーク負荷を減らす役割もあります)
また、リアルタイムETL(ストリーミングETL)と呼ばれる、データが更新され次第、即座にETLのプロセスを実行してくれるツールもあります。こうしたツールを活用すれば、現代の激しい市場の変化や顧客ニーズの変動に対し、迅速に対応できる体制を構築できます。
コンプライアンス対応とセキュリティの強化
ETLツールがカバーするのは、業務効率化だけではありません。業界規制やコンプライアンスへの対応、データガバナンスの構築にも役立ちます。
ETLツールのログ管理機能を活用することでデータの変更履歴や処理の流れを可視化し、監査証跡(audit trail)※7を確保できます。
※7 監査証跡:システム監査を行う際の資料となるログデータのこと
いつ、誰が、どのデータを、どのように処理したかをメタデータとして記録することで、何か事故が起きた際の対応の迅速化や、監査の際の証跡提示に役立ちます。また、ETLツールには詳細なアクセス権限の設定やデータ暗号化機能もあるので、機密情報の保護を強化でき、個人情報保護法や業界固有の規制への対応の効率化が期待できます。
ETL活用の具体的なユースケース

ETLは実際のビジネスシーンで幅広く活用されています。ここでは、ETLの具体的な活用事例を紹介し、どのようにビジネス課題の解決に貢献しているかを解説します。
BI(ビジネスインテリジェンス)での活用
ETLツールの活用でよくあるケースとしては、ETLとDWHを連携させてデータを一元管理し、BI(ビジネスインテリジェンス)ツールでデータ分析を行う、というのが最も一般的でしょう。
たとえば、複数店舗を展開する小売企業の場合、各店舗のPOS※8 システムから、売上・顧客情報・在庫など各種のデータを、日次・週次・月次でETLを用いて収集し、DWHに集約。ETLプロセスによって統合・可視化されたデータをBIツールで分析する、という使い方が考えられます。
こうした経営ダッシュボードの構築によって、経営層は常に最新の指標を把握でき、これからの企業戦略やマーケティングなどに活かすことができます。複数店舗のPOSデータを一元化し、BIツールでの分析に活用することにより、地域別・商品別・時間帯別など多様なサブジェクトでの分析が可能になり、意思決定において多角的な視点を持つことができるようになります。
ETL・DWH・BIの連携は、エンタープライズ企業を中心に、データドリブン経営の基盤を支える中核的な技術として広く導入されています。
※8 POS:Point of Sales(販売時点情報管理)
業務自動化での活用
これまでにも述べたように、ルーティンワークの自動化・効率化はETLの主要な活用手段です。特にリアルタイムあるいは定期的なデータ収集に基づく、日次・週次・月次の定型レポート作成の自動化において、ETLは広く活用されています。
複数システムのデータを統合し自動でレポートを生成することで、手作業における時間や労力を削減する業務効率化を生むだけでなく、手作業で常に懸念されるヒューマンエラーをも防止できます。財務報告や営業報告、KPIダッシュボードなどがETLによって自動生成されることで、月次決算の早期化も期待できます。
また、ETLを業務時間外(夜間・週末)に実行することで業務中のネットワーク負荷を防ぎ、業務への影響を最小限に抑えることができます。
データ分析×機械学習での活用
最新の情勢では、データそのものの利活用のみならず、AI(人工知能)の機械学習モデルにETLを活用するケースが増加しています。
IBMの資料では、リアルタイムで得られたデータをエンタープライズ人工知能に即座に流し、自動的かつ即座に在庫や価格の調整を行うケースが報告されています。また、ETLによって得られたデータを機械学習モデルに最適化された形に変換する、いわゆる機械学習モデルの特徴量エンジニアリングに活用する事例も併せて報告されています。
参考:IBM『特徴量エンジニアリングとは』
これからの経営判断やニーズへの即応的な施策は、ETLによるリアルタイムなデータ供給と、クラウドを前提とした場所と時間を問わないネットワーク環境、AIによる機械学習を組み合わせることで、よりアジャイルな形に進んでいく可能性があります。
参考:IBM『最新のETL:エンタープライズAIの頭脳』
また、ETLのデータクレンジングによる定期的かつ反復的な品質向上も、機械学習モデルの精度改善に活かせる可能性があります。データ・ラングリング※7と連携し、機械学習モデルの自動的かつ継続的な学習をETLツールと掛け合わせて実現し、より高度な分析の土台とするケースも考えられます。
※9 データ・ラングリング:未加工のデータを、データサイエンスや機械学習などのデータ駆動型アプリケーションで使用できる形に整えること
ETLを導入する際に意識するべきポイント

ETLは、範囲の限られたローカルデータ分析ではなく、全社横断的な散在データの活用においてこそ真価を発揮します。ETLの導入を成功させるには、技術導入的な側面のみならず、組織的な取り組みも重要です。ここでは、ETL導入を成功させるために特に意識すべきポイントを解説します。
「データ人材」育成を前提としたデータに強い組織作り
ETLでは、適切かつ安定的な運用のための組織体制の構築が成功の鍵となります。ETLのみの話ではありませんが、データドリブンな企業経営において、データサイエンティストやデータ利活用に強い人材の適切な配置・採用・育成が重要である(外部リソースの活用含む)と言及されています。
参考:経済産業省『データ利活用のポイント集』
分析力やスキル面の育成だけでなく、最新のIT技術動向、法的保護やコンプライアンス対応、情報資産管理、データガバナンスやデータセキュリティの観点を盛り込んだ、包括的かつ全社的な社内研修の実施、ベンダー提供のトレーニングプログラムなどが有効です。
このように全社的にデータドリブンな体制を構築する上では、エンジニア職以外でもデータの利活用が可能な「ノーコード/ローコード型ETLツール」の導入も大切です。部門を問わず活用できる設計書、運用手順書の作成のほか、業務の属人化を防ぐための標準化とマニュアル整備を行い、誰でも同じ品質で作業できる環境を構築すべきでしょう。
コスト管理や投資対効果をシミュレーションする
ETLツールには色々な種類があり、種類によって導入・運用にかかるコストは異なります。導入の際にはどうしても導入コストを見てしまいがちですが、導入コストだけでなく、運用コストも含めた総所有コスト(TCO)を算出することが重要です。
ライセンス費用、インフラコスト、人件費、保守費用などを総合的に評価しましょう。クラウド型ETLツールの場合は従量課金制が多いため、使用量に応じた課金体系をシミュレーションすることが必要です。また、導入による業務時間削減・エラー削減率・レポート作成時間短縮などの定量的な効果測定も欠かせません。
導入したらそれで終わり、と放置してはいけません。経営層も巻き込み、都度キャッシュフローの最適化と改善を繰り返し、費用対効果の最大化に向けて体制やコストをブラッシュアップし続けることが大切です。
大企業では、大規模法人向けのエンタープライズライセンスや専用サポート契約を含めた包括的・長期的な投資を検討しましょう。一方、中小企業では拡張性が柔軟で初期投資を抑えられるクラウド型・従量課金型のETLツールを活用し、「小さく始めて段階的に拡大」のスキームが推奨されます。
データ品質管理のルール設計を徹底する
データ分析においては、データ品質の高さが非常に重要です。
近年の生成AIの普及に伴い、データ分析の世界における「Garbage In, Garbage Out(GIGO)」の原則が、非エンジニアにとっても実感を伴うようになりました。これは、「ソースデータの品質が悪いと、変換後のデータも品質が低くなる」原則のことです。この原則に照らせば、最適な意思決定を得るためには、ロードするデータの品質を上げなければならないのです。
参考:独立行政法人情報処理推進機構(IPA) デジタル基盤センター『データ品質SWGの設立背景と取組状況について』
データ利活用においてGIGOを防ぐためには、データクレンジングのルール設計や、データバリデーション(検証)の仕組み作りを念入りに行う必要があるでしょう。データの不正確の基準、欠損値の処理の仕方、重複データの検出方法や統合方法などを明確に定義することで、より確度の高いデータを得るための基盤が強固なものとなるはずです。
ETLプロセスにデータ検証工程を組み込むことでも、問題の早期発見が可能になるでしょう。
スケーラビリティの確保
ETL導入の際は、拡張性(スケーラビリティ)が担保された柔軟な設計が大切です。
将来的なビジネス成長と、それに伴うデータ量の増大を想定し、拡張性のあるアーキテクチャを選択しましょう。スケーラビリティが難しい設計では、急激なデータ量増大の際にリソース不足となりパフォーマンスが大幅に低下してしまいます。
クラウド型のETLツールであれば、スケーラビリティ的には比較的柔軟であることが多いので、需要に応じてリソースを増減できます。
しかしただ増やせばいいというものでもなく、並列処理(複数のデータソースから同時に抽出)や増分処理(差分データのみを処理)を活用し、バッチ処理の最適化も併せて行うといいでしょう。こうした最適化を行って無駄なデータ量の増大を抑えつつ、高品質なデータ量の増加を見越した設計をしておくと、急なデータ量によるリソース逼迫時にも落ち着いて対応できる環境が整います。
セキュリティ対策やコンプライアンス体制を整える
ETLのプロセスを前提としたデータドリブンな体制の構築を行う上では、セキュリティ対策を設計段階から組み込むことが不可欠です。
まずは、アクセス制御や権限管理の徹底を行い、「誰がどのデータにアクセスできるのか」を明確にします。その上で、データの暗号化(転送時・保管時)やマスキングなど、データの変更や移動のプロセスにおけるセキュリティ対策を整えます。
その上で、監査証跡を確保するためのデータログの記録と保管を行い、万が一コンプライアンスに関わる問題が起きた時に「いつ、誰が、どのデータを処理したか」の履歴を参照できる環境を整えましょう。併せて、個人情報保護法や業界規制への対応も必要です。
ETLはデータ活用の第一歩

企業内のさまざまなシステムに散在するデータを収集・整形し、DWH(データウェアハウス)に一元的に格納するETLは、データドリブン経営の基盤となる重要なプロセスです。
ETLプロセスを効率化・自動化できるETLツールの導入は、手作業のリスクのほぼ全てを解消できるので、データ品質の向上、迅速な意思決定につながります。これからの企業にとって避けては通れないDX推進においても、ETLによる高品質なデータ基盤があってこそ効果的なDXが展開できる、といっても過言ではないでしょう。適切な計画と運用体制のもとでETLを導入することで、データドリブンな意思決定を実現し、企業価値の向上・競争優位性を確立することが可能になるでしょう。「データ活用の第一歩」としてのETLの活用が、必ずや企業の成長・発展に結びついていくはずです。
GREEN CROSS PARKのDX

東急不動産株式会社が推進する 「GREEN CROSS PARK(グリーンクロスパーク)」 は、 まち全体に先進的なDX基盤を整備する構想を掲げた、新しい産業団地です。 超高速通信環境や自動運転などの最先端技術を導入し、 参画企業のデジタル化・業務効率化・新たな価値創出を支援します。 また、工業用地の活用を検討する企業や、GX・DXといった次世代経営テーマに取り組む皆さまにとって、 産業振興と地域共創を両立するモデルケースとなることを目指しています。